For more details or help support please contact with
Support Team
finhub-support@nsdc.fmi.fi
The Data Hub exposes two dedicated Application Program Interfaces (API) for browsing and accessing the EO data stored in the rolling archive. The APIs are:
The OData interface is a data access protocol built on core protocols like HTTP and commonly accepted methodologies like REST that can be handled by a large set of client tools as simple as common web browsers, download-managers or computer programs such as cURL or Wget.
OpenSearch is a set of technologies that allow publishing of search results in a standard and accessible format. OpenSearch is RESTful technology and complementary to the OData. In fact, OpenSearch can be used to complementary serve as the query aspect of OData, which provides a way to access identified or located results and download them.
- Open Data Protocol (OData)
- URI Components
- Responses
- Using OData to discover products in the Data Hub archive
- Download
- Open Search
- Batch Scripting
Open Data Protocol (OData)
The Open Data Protocol (OData) enables the creation of REST-based data services, which allow resources, identified using Uniform Resource Identifiers (URIs) and defined in a data model, to be published and consumed by Web clients using simple HTTP messages.
The OData protocol provides easy access to the Data Hub and can be used for building URI for performing search queries and product downloads offering to the users the capability to remotely run scripts in batch mode.
A URI used by an OData service has up to three significant parts: the Service Root URI, the Resource Path and the Query Options.
- the Service Root URI identifies the root of the OData service
- the Resource Path identifies the resource to be interacted with. The resource path enables any aspect of the data model (Data Hub Products, Data Hub Collections, etc.) exposed by the OData service
- the system Query Options part refines the results
Example of and OData URI exposed by the Data Hub Service broken down into its component parts:
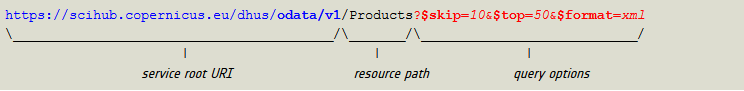
OData Service Root URI for the Data Hub:
-
https://finhub.nsdc.fmi.fi/odata/v1/
Data Hub Resource Paths:
-
/Products -
/Collections
-
$formatSpecifies the HTTP response format of the record e.g. XML or JSON -
$filterSpecifies an expression or function that must evaluate to true for a record to be returned in the collection -
$orderbyDetermines what values are used to order a collection of records -
$selectSpecifies a subset of properties to return -
$skipSets the number of records to skip before it retrieves records in a collection -
$topDetermines the maximum number of records to return
-
https://finhub.nsdc.fmi.fi/odata/v1/Products?$orderby=IngestionDate%20desc&$top=100
lists the records of the last 100 products published on the Data Hub -
https://finhub.nsdc.fmi.fi/odata/v1/Products?$orderby=IngestionDate%20desc&$top=100&$skip=100
skips the first 100 records of the products published on the Data Hub and then returns the next 100
When users query the Data Hub via the URI, the request is sent to the Data Hub OData service. This service provides the responses. The description of the responses is provided here below focusing on the response body and not covering the standard HTTP response envelope.
The default response format is Atom [RFC4287], an XML-based document format that describes Collections of related information known as 'feeds'. The responses containing a single Product entity differ from those containing a collection of Product entities. Generally speaking, the single Product entity is returned as a bare Atom entry element, while for a collection the same Atom entries denoting the Product entities are wrapped into an Atom feed element.
The response format can however be controlled from the requests through the $format query option already introduced above. The formats currently implemented by Data Hub service are Atom (or XML) and JSON which is a non-standard output of OData but is an experimental behaviour useful for EO context.
The following sub-sections describe the response types for Atom/XML and JSON output formats. The very last sub-section deals with the specific responses returned in case of error.
The Atom/XML format is the default response format, though it can be forced by setting the $format query option to 'atom' or 'xml' indifferently as in the following examples:
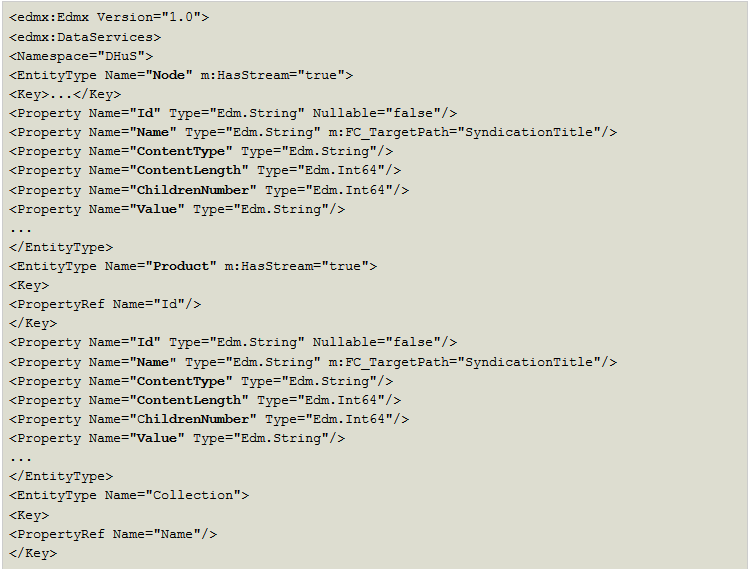
In order to help clients discover the OData services, the Data Hub OData Service Metadata Document exposes the Entity Data Model of the service including among others, the Entities and Properties that can be queried.
This document can be queried as with the following URL:
The following example is extracted from the complete Service Metadata Document exposed by a Data Hub OData service. Some sections or XML Namespace declarations have been removed for brevity:
The following OData URI addresses the resource 'Products' exposed by the Data Hub Service which includes the records of all the products stored in the Data Hub archive. Each product record includes the Universally Unique Identifier (UUID), the product name, the link for download, the links for navigating through their nodes and attributes and some properties.
The syntax is:

Example:
By default it provides a list of 50 records showing the properties of the latest 50 products ingested by the Data Hub.
Examples of properties are:
-
IngestionDate - date on which the Product was ingested by the contacted Data Hub instance. The date referential is UTC.
-
ContentDate (Start and End) - time period associated to the Product payload. This date regards the period of the subject of the content and not the content itself. For example, for an EO product, the ContentDate deals with the observation date and not to the downlink or processing dates.
-
ContentGeometry - footprint polygon coordinates
The universally unique identifier (UUID) is a standard identifier used in software construction to uniquely identify information without significant central coordination. A UUID is a 16-octet (128-bit) number.In its canonical form, a UUID is represented by 32 lowercase hexadecimal digits, displayed in five groups separated by hyphens, in the form 8-4-4-4-12 for a total of 36 characters (32 alphanumeric characters and four hyphens).
The responses containing a single Product entity differ from those containing a collection of Product entities. Generally speaking, the single Product entity is returned as a bare Atom entry element, while for a collection the same Atom entries denoting the Product entities are wrapped into an Atom feed element.
Syntax:

The following example is an actual response of a Data Hub OData service that returned a single Product entity identified by the UUID: 18f7993d-eae1-4f7f-9d81-d7cf19c18378.
Again, this snippet has been reformatted for readability purpose but nothing has been removed from the actual response:
https://finhub.nsdc.fmi.fi/odata/v1/Products('18f7993d-eae1-4f7f-9d81-d7cf19c18378')
Response:

The URI to be used for paging the list of products in the archive shall follow the syntax below:

where ?$skip='N' is the number of records to skip before it retrieves records in a collection and is the maximum number of records to return.
Example:
-
https://finhub.nsdc.fmi.fi/odata/v1/Products?$skip=10&$top=50
this OData URI allows to list 50 products skipping the first 10.
ATTENTION: $top accepts as maximum value 100. For higher values it will result in an error ( http 500 ).
It is possible to use the OData properties to perform search query to filter the products.
For the metadata that are expressed in the UTC format such as
| Filter | Description |
|---|---|
| CreationDate | For future implementation |
| IngestionDate | Time of the products archiving in the Data Hub |
| EvictionDate | For future implementation |
| ContentDate/Start and ContentDate/End | TBW |
the filter can be performed on the day and/or month and/or year.
The symbols are not allowed in the OData protocol but they are substituted with the following syntax:
| Symbol | Regular Expression | Meaning |
|---|---|---|
| < | lt | lower than |
| ≤ | le | Lower or equal than |
| > | gt | Greater than |
| ≥ | ge | Greater or equal than |
| = | eq | Equal |
Here below we provide some examples.
To filter the products by Ingestion Date, the following syntax may apply:

Examples:
-
https://finhub.nsdc.fmi.fi/odata/v1/Products?$filter=year(IngestionDate)%20eq%202014%20and%20month(IngestionDate)%20eq%2012
This URI selects the products that have been published in the Data Hub on December 2014
-
https://finhub.nsdc.fmi.fi/odata/v1/Products?$=IngestionDate%20gt%20datetime%272014-12-06T00:00:00'
This URI selects the products that have been published in the Data Hub after 06 Dec 2014
The products file name can be used for filtering the products. It shall be noticed that this query criteria is not based on the Medatata indexed from the products content but the criteria is search products matching a predefined string on the file name.
In this case, the Entity Data Model (EDM) string are used for metadata like Name which indicates the name of the product. Every metadata containing a string can be filtered using the substringof filter.
Examples:
-
https://finhub.nsdc.fmi.fi/odata/v1/Products?$select=Id&$filter=substringof('SLC',Name)
This OData URI lists the products having SLC in the file name.
To filter the products by the Sensing Time (start and stop) it can be used the S1 product filename, using the filter substringof. Next section will describe how to make query based on indexed metadata.
The syntax is:

Example:
-
https://finhub.nsdc.fmi.fi/odata/v1/Products?$select=Id&$filter=substringof('_20141118T073253_',Name)
This OData URI lists the products having in the file name the string20141118T073253. It means it returns the products with a predefined sensing time start (e.g. 2014-11-18, T073253).
OData can be used for querying the values of products metadata content.
To retrieve the UUID of a predefined product, the syntax is:

Example:
-
https://finhub.nsdc.fmi.fi/odata/v1/Products?$filter=Name eq 'S1A_IW_SLC__1SDV_20141101T165548_20141101T165616_003091_0038AA_558F'this URI retrieves the UUID of the product:
S1A_IW_SLC__1SDV_20141101T165548_20141101T165616_003091_0038AA_558F
OData URL can be used for download full products as well as partial products by using the combination of the Nodes and Attributes indexed for the products and adding at the end of the URI.
To download a full products the syntax is:

Example:
Products from all processing levels (Level-0, Level-1 and Level-2) are disseminated in SENTINEL-SAFE format. The data delivered is packaged as a file structure containing a manifest file in XML format listing general product metadata and subfolders for measurement data, annotations, previews and support files. The SENTINEL-SAFE format wraps a folder containing image data in a binary data format and product metadata in XML. This flexibility allows the exploration of parts of the products without download the complete product.
In this section we will provide examples to how explore products nodes.
The following URI will return the XML file including the list of the first level nodes:

Generally the first node is the one whose name is [Product_Name.SAFE] and the URI to visualize the XML schema of this node is the following:

Example of the nodes of a level-1 Sentinel Product are:
- Manifest.safe
- Annotation
- Measurement
- Preview
- Support
To download manifest file from the UUID the syntax is:

Example:
To download the quick-look file from the UUID the syntax is:

Example:
This can help to reveal if the download was incomplete.
Each product published on the Data Hub provides an MD5 checksum of the downloadable ZIP file.
The Message Digit of the file can be discovered using the following OData query:

where UUID is the Universally Unique Identifier of the product. Example:
provides the following MD5:
-
99F8BCE665CEF2587258F581873DFA53
The integrity of the downloaded product can be checked by comparing the MD5 value of the product at the source with the MD5 of the product located on the users's system. If they are identical the download has been succesfull.
Different Operating Systems require different methods for verifying the checksum of the downloaded products.
Find below a list of the most common ones:
Open a terminal and type:
-
md5sumpath/filename
Open a terminal and type:
-
md5path/filename
The File Checksum Integrity Verifier (FCIV) utility does not come pre-installed on windows and needs to be downloaded. Instructions can be found here.
Open a command prompt and type:
-
FCIV-md5-sha1path ilename
This method can be done on any system with OpenSSL installed (i.e. Windows, Linux and MAC). Open a command prompt or terminal and type:
-
opensslmd5path/filename
OpenSearch (Solr) is a set of technologies that allow publishing of search results in a standard and accessible format. OpenSearch is RESTful technology and complementary to the OData. In fact, OpenSearch can be used to complementary serve as the query aspect of OData, which provides a way to access identified or located results and download them. The Data Hub implementation uses the Apache Solr search engine.

where:
-
<dhus_hostname>:<port>/<path>is the Service Root -
search?q=<query>is the Query
The syntax is:

Example:
-
https://finhub.nsdc.fmi.fi/odata/v1/search?q=*
The above URI returns an XML file including the list of the nodes of every products stored in the Data Hub archive. By default only 10 results are shown.
A query can be completed with the pagination options. The available options are:
rows=<page_size>, wherepage_sizeis the number of results listed per pagestart=<page_start_value>wherepage_start_valueidentifies from which result position starts the pagination
If nothing is specified by default page_size and page_start_value are set to rows=10 and start=0 .
ATTENTION: The maximum number of rows to be returned in a single query is set to 100. Requests for more than the maximum supported number of rows will result in an error ( http 500 ).
Results sets over the maximum can be obtained through paging of from different start values.
- Page 1:
https://finhub.nsdc.fmi.fi/odata/v1/search?start=0&rows=100&q=* - Page 2:
https://finhub.nsdc.fmi.fi/odata/v1/search?start=100&rows=100&q=* - Page 3:
https://finhub.nsdc.fmi.fi/odata/v1/search?start=200&rows=100&q=*
It is possible to search products on the basis of a geographical area of interest, e.g. get the list of products over a geographic area delimitated by the polygon having vertices:

The <geographic type> value can be expressed as a polygon or as a point according to the syntax described below.

where P1Lon and P1Lat are the Longitude and Latitude coordinates of the first point of the polygon in decimal degrees (DDD) format (e.g. 2.17403, 41.40338) and so on.
The coordinates of the last point of the polygon must coincide with the coordinates of the first point of the polygon.
The polygon describing the geographical area can have a maximum of 200 points that must be within an area described by 10 degrees of latitude and 10 degrees of longitude.
Example:
-
https://finhub.nsdc.fmi.fi/odata/v1/search?q=footprint:"Intersects(POLYGON((-4.53 29.85,26.75 29.85,26.75 46.80,-4.53 46.80,-4.53 29.85)))"
is a bounding box around the Mediterranean Sea

where the Latitude ( Lat ) and Longitude ( Lon ) values are expressed in decimal degrees (DDD) format (e.g. 41.40338, 2.17403 ).
Example:
The [query] in the open search URI will follow the same syntax used in the full text search. Here below we provide some examples.
| Example | Open Search |
|---|---|
| Searches every product with SLC product type or products containing the string "SLC" in the metadata | https://finhub.nsdc.fmi.fi/search?q=SLC |
| Searches every product with SLC product type and S1 sensor Mode or products containing the strings "GRD" and "S1" in the metadata | https://finhub.nsdc.fmi.fi/search?q=GRD AND S1 |
| Search every products ingested in the last day | https://finhub.nsdc.fmi.fi/search?q=ingestionDate:[NOW-1DAY TO NOW] |
| Search every products ingested in the last month | https://finhub.nsdc.fmi.fi/search?q=ingestionDate:[NOW-30DAYS TO NOW] |
| Search every products ingested in the last hour | https://finhub.nsdc.fmi.fi/search?q=ingestionDate:[NOW-1HOUR TO NOW] |
| Search every products ingested in the last day with GRD product type | https://finhub.nsdc.fmi.fi/search?q=productType:GRD AND ingestionDate:[NOW-1DAY TO NOW] |
| Search every products having sensing in the last three months | https://finhub.nsdc.fmi.fi/search?q=beginPosition:[NOW-3MONTHS TO NOW] AND endPosition:[NOW-3MONTHS TO NOW] |
Search every products having polarization mode VV covering the geographic area delimitated by the polygon having vertices: -4.53 29.85, 26.75 29.85, 26.75 46.80,-4.53 46.80,-4.53 29.85 |
https://finhub.nsdc.fmi.fi/search?q=polarisationmode:VV AND footprint:"Intersects(POLYGON((-4.53 29.85, 26.75 29.85, 26.75 46.80,-4.53 46.80,-4.53 29.85)))" |
Other details and further examples are illustrated in the Full Text Search section.
The above OData and OpenSearch URIs can be combined to create complex queries to be executed in non-interactive scripts using programs like cURL and Wget.
Using cURL it is possible to create a script to login to the Data Hub via the following command line:

where:
-
-u: option to specify user and password to use when fetching - <URI_QUERY> is a valid OData URI or OpenSearch URI.
It is possible to use the wget command to create batch scripts:
It is possible to use the wget command to create batch scripts:

where {USERNAME} is the valid account username, {PASSWORD} is the corresponding authentication password value and {FILE} is the name of the file where to print the output of the query. If '-' is used as {FILE}, documents will be printed to standard output.
The following example shows how to make an OpenSearch query using Wget. The query searches for all the products in the Data Hub archive. The first 25 results are printed in a file named query_results.txt:
-
wget --no-check-certificate --user={USERNAME} --password={PASSWORD} --output-document=query_results.txt 'https://finhub.nsdc.fmi.fi/search?q=*&rows=25'
The following example shows how to make an OpenSearch query using Wget for searching products filtered by product type and ingestion date :
-
wget --no-check-certificate --user={USERNAME} --password={PASSWORD} --output-document=query_results.txt 'https://finhub.nsdc.fmi.fi/search?q=ingestiondate:[NOW-1DAY TO NOW] AND producttype:SLC&rows=1000&start=0&format=json'
It is also possible to download the products from the Data Hub archive using wget .
The following example shows how to download a single product, identified by its own Data Hub universally unique identifier {UUID}, using an OData URI:
-
wget --no-check-certificate --continue -user={USERNAME} --password={PASSWORD} 'https://finhub.nsdc.fmi.fi/odata/v1/Products('{UUID}')/'
The option --continue is very useful when downloads do not complete due to network problems. Wget will automatically try to continue the download from where it left off, and repeat this until the whole file has been retrieved.
The following example shows how to download the manifest file of a Sentinel-1 product using and Odata URI with Wget. onlyidentified by the universally unque identifier {UUID}:
-
wget --no-check-certificate --user={USERNAME} --password={PASSWORD} "https://finhub.nsdc.fmi.fi/odata//v1/Products('{UUID}')/Nodes('{PRODUCT_FILENAME}')/Nodes('manifest.safe')/"
where {UUID} is the value of the the universally unique identifier of the product, and {PRODUCT_FILENAME} is the filename of the product.
The example (dhusget) is a simple demo script illustrating how to use the OData and OpenSearch to query and download the products from the DHuS. It allows:
- Search products over a pre-defined AOI
- Filter the products by products type and/or ingestion time
- Download the products
- Download the manifest files only
You can download the script here
It requires the installation of wget .
Usage:
# dhusget.sh [-d <!DHuS URL> ] [-u <username> ] [ -p <password>] [-t <time to search (hours)>] [-c <coordinates ie: x1,y1;x2,y2>] [-T <product type>] [-o <option>]
The options are:
-
-u <username>: data hub username provided after registration on <!DHuS URL> -
-p <password>: data hub password provided after registration on <!DHuS URL> (note: it's read from stdin, if isn't provided by command line) -
-t <time to search (hours)>: time interval expressed in hours (integer value) from NOW (time of the launch of the dhusget) to backwards (e.g. insert the value '24' if you would like to retrieve product ingested in the last day) -
-f <file>: a file containing the time of last successfully download -
-c <coordinates ie: lat1,lon1:lat2,lon2>: coordinates of two opposite vertices of the rectangular area of interest -
-T <product type>: product type of the product to search (available values are: SLC, GRD, OCN and RAW) ; -
-o <option>: what to download; possible options are:-
'manifest'to download the manifest of all products returned from the search or -
'product'to download all products returned from the search -
'all'to download both
-
N.B.: if this parameter is left blank, the dhusget will return the UUID and the names of the products found in the DHuS archive.
The script odata-demo is a demo script performing the following selective actions:
- List the collections
- List <n> products from a specified collection
- List first 10 products matching part of product name
- List first 10 products matching a specific ingestion date
- List first 10 products matching a specific aquisition date
- List first 10 products since last <n> days, by product type and intersecting an AOI
- Get product id from product name
- Get polarisation from a product id
- Get relative orbit from a product id
- Download Manifest file from a product id
- Download quick-look from a product id
- Download full product from its id
You can download the script here
It requires the installation of xmlstarlet .
Usage:
# odata-demo.sh [OPTIONS]
The options are:
-
-h, --helpdisplays a help message -
-j, --jsonuse json output format for OData (default is xml) -
-p, --passwd=PASSWORDuse PASSWORD as password for the Data Hub Server -
-s, --server=SERVERuse SERVER as URL of the Data Hub Server -
-u, --user=NAMEuse NAME as username for the Data Hub Server -
-v, --verbosedisplay curl command lines and results -
-V, --versiondisplay the current version of the script
back to top © ESA